Innovation
How We Built: An Early-Stage Recommender System
Shayak Banerjee, David Stevens, Santosh Thammana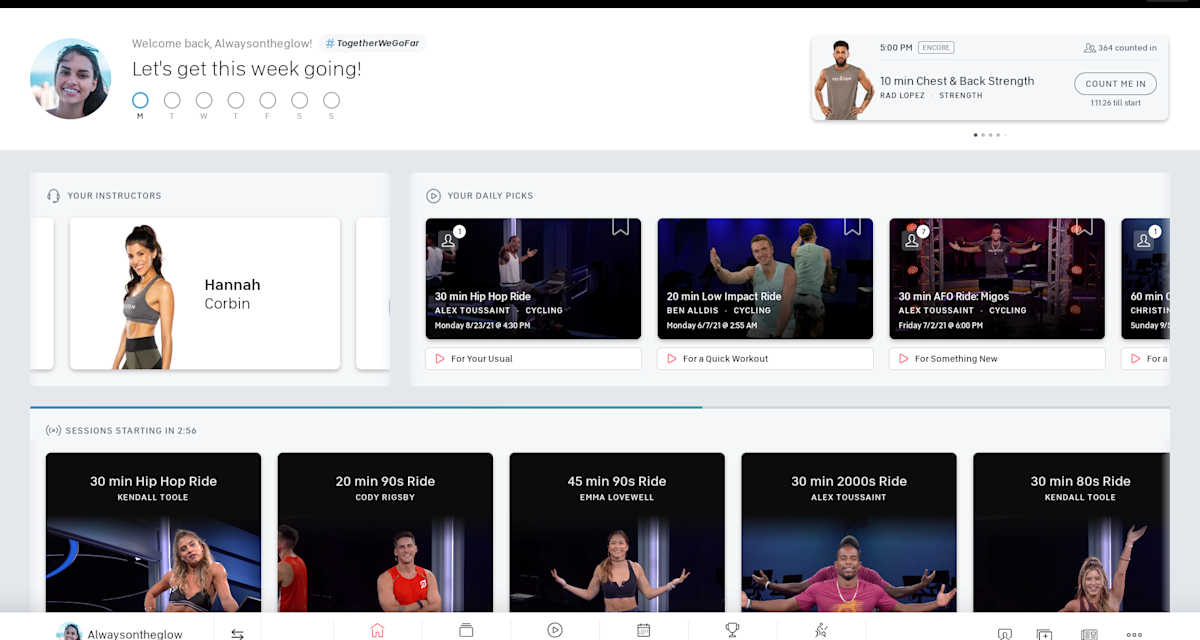
Personalization is ubiquitous on most platforms today. Supercharged by connectivity, and scaled by machine learning, most experiences on the internet are tailored to our personal tastes. Peloton classes offer a diversity of instructors, languages, fitness disciplines, durations and intensity. Each Member has specific fitness goals, schedule, fitness equipment, and level of skill or strength. This diversity of content and individuality of Member needs at massive scale creates the opportunity for a recommender system to create a personalized experience on the Peloton platform. Our Personalization team at Peloton is constantly discussing new techniques and approaches to connect our Members to the right piece of content at the right time in the right context. We have a talented team and routinely discuss new publications and papers in the machine learning space to see how they can be applied to our unique community. A group of us participated at RecSys 2021 with other industry leaders. But it wasn't always this way - in this article we're going to talk about how the Personalization team came to be with some data-driven examples and hypotheses, so you can pursue the same process in your organization. We'll also cover why, whilst these are enough to get a team established, they are likely not enough for all the things that you want to do with recommendations for your use case.
At the beginning of this journey, in late 2019, we were looking to update the iconic Peloton Bike and Tread homescreens. Based on what we were hearing from our Members, we wanted to make it more modular and personalized. We were tasked with powering some specific rows on this redesigned screen. At Peloton Engineering we are constantly working to respond to the feedback of our ever growing community. One of our initiatives involved personalizing the Home screen. In this article we will be diving deep into just one of those aspects: Your Daily Picks. The Daily Picks row originally had a few class suggestions for the Member, with a short reason for suggesting it. The three most prominent cards suggest For Your Usual, For a Quick Workout and For Something New. We have since gone through three distinct phases where we tested a specific hypothesis at each phase.
Phase 1: Proving the Value of Suggestions
In the very early days when our team first set out, our initial hypothesis was that: Members are interested in a set of suggested classes in lieu of picking their way through our entire library of live and on-demand classes.
In this phase, the primary engineering concern was presenting a set of suggestions to the Member, with little need to focus on driving those suggestions with machine learning. We picked a simple set of heuristics, which involved accounting for the Member’s most frequent duration / type of workout and their most frequently used instructor.
We computed recommendations for all Members offline, cached them and served them up when requested. Two factors drove this decision:
Recommendations could be refreshed at a daily cadence without degrading the user experience.
We were averse to querying workout histories in real-time from our transactional database before we had a chance to apply these heuristics.
With a very small team, developing and maintaining infrastructure from scratch was a challenge, especially since recommendations needed to be generated for millions of Peloton Connected Fitness Members. The figure above shows our early system for computing recommendations in batch and serving them up when requested via the API. It was important for us to use managed cloud services like Azure Data Factory, Stitch etc. for our batch preprocessing. We chose AWS managed services like Glue and Lambda, and AWS managed databases like DynamoDB, to ease the operational burden on a small team. We also utilized Glue Triggers to chain this sequence of processing steps together, primarily because the ability to jointly provision compute machinery and schedule them was appealing at this stage.

Our first system for serving recommendations, computed based on heuristics
With this infrastructure in place we were able to realize a number of quick wins. We released the Daily Picks row to the Peloton Bike and Tread+ home screens. We got a lot of great qualitative feedback as a result. Feedback from internal users suggested that recommendations were picking up on the types of classes they usually took. We also received quantitative signals by tracking (anonymously) how many Members took classes from this row. It should be called out that we take our members’ privacy as paramount and treat all customer data with the utmost sensitivity. With a mix of qualitative and quantitative signals, we successfully proved our hypothesis. There was indeed value to personalizing the Peloton experience by providing suggested classes for Members, making it easier for them to find the types of classes they most frequently interact with.
Phase 2: Proving the Value of Machine Learning
In the second phase, we asked the question: Can machine learning algorithms improve the quality of recommendations?
With our simple heuristics we anecdotally saw an opportunity for us to recommend far more appropriate content for Members. For example, a user saw the same 30 minute Jess King 7-year Anniversary Ride several sessions in a row. This is a class best taken live, and there were newer 30 minute Jess King rides available to recommend. We also did not adapt to users ignoring certain recommendations. However, the team was still new and we had not yet built the foundational blocks of an ML team, such as model servers or model training infrastructure. After all, how do we invest in ML without first proving its value?

In its second version, the system generated ML-driven recommendations, scheduled by Airflow
While Glue’s managed compute resources had helped kickstart us, running GPU-intensive machine learning jobs was not a supported capability. Further, Glue Triggers for scheduling were only usable with Glue jobs. To address these infrastructural concerns, as well as address recommendation quality, we built the Phase 2 system shown in the above figure. The biggest changes were:
Utilizing AWS Personalize to generate the For Your Usual module, and running this job on Kubernetes
For scheduling, replacing Glue Triggers with Airflow.
Using our Platform Team’s newly developed Kubernetes tooling to both run Airflow and replace our serving infrastructure.
We ran an A/B test for the model-generated recommendations vs. the heuristics-based ones for For Your Usual, where we saw a clear lift in usage metrics for this placement. This made the case for using ML-generated recommendations clear. Demonstrating the value of ML also enabled us to grow the team, which was important for Phase 3.
An interesting side-effect of this phase was that we still kept our former rules-based pipelines running concurrently. This was partly because we had not yet replaced the other placements with ML, but also because the heuristics generated recommendations served as fallbacks. These fallbacks were necessary for (a) days on which the model training might fail, and (b) for Members who may not have had recommendations generated, either due to being new to the platform or having been inactive for a long time.
Phase 3: Making the Case for an In-House Model
Around this time, we honed in on the concept that our recommendations could be generated by combining a ranker with a filter. A ranker is a way to logically order the universe of Peloton content for each Member. This is where personalization often kicks in. The ranking of content is best generated by Machine Learning models by considering the overall engagement of our members like interacting with a class, liking an instructor etc. A filter is a way to then display a slice of that ranked list to Members. An example is in the below figure where we can take a ranking model optimizing for Member converting on a class, and filter the ranked list of classes down to the short duration ones (20 minutes or less) to serve up a row called For A Quick Workout.

Creating rows of recommendations by combining a filter and a ranker.
AWS Personalized proved useful as a temporary solution but we quickly uncovered a number of limitations.
We were only able to get a list of top recommendations per Member from AWS Personalize, with no scores (relative likelihood to convert) attached. This was particularly problematic because we could not tell if the second-placed recommendation was equally likely, or ten times less likely, to convert as the first placed one.
With just a handful of top recommendations, it was difficult to incorporate more unique business needs such as promotions, or Member needs such as their content preferences. We needed sizable lists of ranked classes per Member from the service, which was not cost effective or even supported by AWS Personalize at the time.
The cost of AWS Personalize did not scale well to using it for other rankers, such as a model that optimized for Members liking tracks.
Now, our question morphed to: Is there value to building out an in-house model? We had modeling experience on the team but lacked some of the foundational tools required for content-based models, such as a feature store. This led us to develop a deep learning based, collaborative filtering model that primarily utilized the Member - class interaction data. We will describe this model in more detail in a follow-up post.
When running Spark jobs, we encountered several issues with AWS Glue’s compute, namely:
Difficulty of getting a working development environment with Glue notebooks, which led to a lot of testing in production.
Lack of guidance when tuning cluster configurations, primarily due to the lack of a Spark UI meant that we often ended up over-provisioning.
Cumbersome and manual deployment process, mainly driven by the inability to deploy containers and having to copy over packaged dependencies instead.

Creating rows of recommendations by combining a filter and a ranker.
In this phase, we made several structural changes to support an in-house model:
Utilizing Amazon’s Elastic MapReduce (EMR) service for all pre- and post-processing of data. The development experience using EMR notebooks, the deployability of containers, and the tunability of clusters with the help of the Spark UI drove this change from using Glue.
Using Airflow to orchestrate these batch jobs on EMR, with our own custom operators.
Building out deep learning model training and predictions using PyTorch on GPUs.
Using MLFlow, running on Kubernetes, as a model storage / tracking service. In addition to serializing and storing the model itself, it keeps track of adjunct information like training data location, hyperparameters, and evaluation metrics.
With our in-house model, we now had access to fully ranked lists of classes with scores. We were now able to power all the aforementioned Daily Picks recommendations instead of just For Your Usual. In an A/B test, we observed large gains on the majority of our placements (which were previously heuristics-driven). This made the switch to an in-house model an easy decision.
Looking Ahead to the Future
Currently, much of our processing happens offline, where we precompute sets of recommendations by ranking and filtering, then cache them for retrieval when requested by the Member. As Peloton has expanded its platforms to TV, iOS and Android, this approach has scaled as well. The cache and retrieval strategy works mostly because the product itself does not invoke the same serial consumption habits as other products. These products recommend short pieces of content like posts, pins and music, of which multiple can be consumed in one session.
As Peloton’s Member Experience continues to diversify, we see a plethora of opportunities for personalizing a Member’s journey on Peloton. We are also cognizant of several deficiencies in our current infrastructure, such as sub-optimal data loading / processing on our GPUs and the lack of a feature store, which blocks utilizing more modern model architectures.
Taking on these problems will make for an interesting next few months at Peloton. Stay tuned for further updates!