Innovation
Lessons Learned from Building out Context-Aware Recommender Systems
Written by Shoya Yoshida, Arnab Bhadury, Neel Talukder, Shayak Banerjee, Alexey Zankevich and Vijay Pappu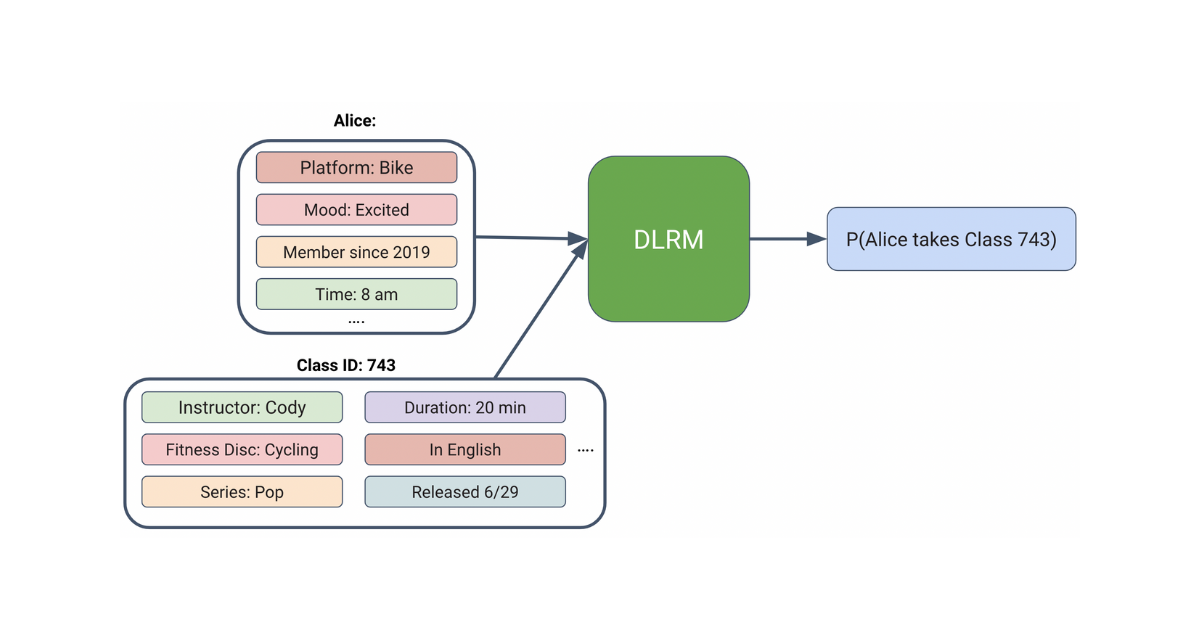
In our previous post, we described the LSTMNet, the model the Personalization team at Peloton chose as our first foray into building machine learning-based recommender systems for our platforms’ home screens. The LSTMNet was an appropriate choice, as data stores were still in their early stages and fragmented, making it hard to use a wide variety of different features. As a result, the LSTMNet that simply learned from sequences of workouts was suitable, in addition to the natural correspondence of the model’s sequential nature and the serial nature of fitness. We also detailed the drawbacks of using the LSTMNet, such as the lack of contextual relevance and its inability to handle cold, or new, items and users.
In this post, we lay out how we have been building out Context-Aware Recommender Systems (CARS) to iterate on the LSTMNet. We will first motivate the need to be context-aware when making recommendations, then dive deep into the lessons we have learned along the way, and finally wrap up with what is planned for ahead.
UNDERSTANDING THE IMPORTANCE OF CONTEXT FOR FITNESS
Fitness is a journey that is unique to each individual with an infinite possibilities of paths. At Peloton, each class is characterized by different themes, music, fitness disciplines, and teaching styles of our world-class instructors, who range anywhere from soothingly tranquil to inspiringly cheerful. Needless to say, user behavior and preferences vary wildly and evolve over time, and it may even change from one context to another even for the same user.
For example, one user may opt to take our flagship live cycling classes with energetic music on Friday nights on the Peloton Bike, while choosing to take our yoga classes in the morning and meditation classes at night using the mobile app on other days. Another user may not have the Peloton Bike, but instead stream multiple strength classes from their smart TV in the living room and afterwards go outside to follow our guided outdoors run class using the Peloton App.
With so many types of different workouts available, users must make many small decisions to choose their workouts of the day. Peloton’s internal User Research team conducted a study and identified five key decision factors that users face when choosing a class. The factors are time, instructor, class type, mood, and recent state; they are all interrelated with one another as shown in the figure below.

Time
Time can be broken down into two interdependent aspects. One aspect of time is the duration that the user is willing to workout, and the other aspect is the time of the day, week, or year when the user is making this decision. Some users may log in looking to do a 30 minute workout because that may be the only time they have available right then. However, the situation could vary on a weekday morning before commuting or the decision may be different if it was on a Saturday afternoon during the holiday season instead. Time can frequently be an unnegotiable decision factor.
Instructor
As mentioned previously, we have a wide variety of world-class instructors with diverse backgrounds and teaching styles. Most of our users have certain favorite instructors that they will take the bulk of the classes with. Depending on their mood, some users may opt to take classes with Cody Rigsby to get some words of affirmation, or opt to take a class with Olivia Amato, an instructor known to lead very challenging workouts, if in a daring mood.
Class Type
With diverse instructors comes diverse classes on various platforms. To run through the numbers, we have three platforms (Peloton Bike and Bike+, Peloton Tread, and digital, which includes the Peloton App and the recently released Peloton Guide), over 50 instructors, 10+ fitness disciplines, and dozens of different series within each fitness discipline. In addition, each class at Peloton has its own curated music playlist to fit the style of the class. Our library of content is diverse enough to fill almost every class type imaginable. From Jess Sim’s “Flash 15” strength workout series that could make you sore in 15 minutes to Dance Cardio to Meditation content with your favorite instructors, our library has something for everyone.
Mood
Mood can affect what kind of vibe one may seek out in a class. Perhaps, it is early Monday morning and one feels the need to reach a sense of calmness and thus opts to take some yoga or stretch classes. Conversely, one may be in a bright mood on a Friday night and opt to take a Groove cycling class to jam out to your favorite music.
Recent State
A user’s recent state surrounding last completed workouts is also important. If one has already taken a lower body strength class and a core exercise class recently, one would likely gravitate towards taking an upper body workout to balance out the muscles used. Within the same workout session, if one just finished a long cycling class, one would want to take a nice 10 minute lower-body stretch class. There are also more external aspects, such as when a user may be injured, and the user must opt to take easier classes than they are normally used to.
All in all, in the realm of fitness, choosing the appropriate class is highly dependent on the real time context of a user. Consequently, an ideal recommender system at Peloton must be context-aware and be able to dynamically adjust to diverse settings a user may be in.
THE LIMITATIONS OF LSTMNET
As explained in the previous blog post, the LSTMNet represents each user with the sequence of classes that the user has been taking. This representation of the user is then compared with the embedding for a specific class to come up with a recommendation score for this user-class pair.
One major limitation of LSTMNet is that it cannot use any contextual information to influence the recommendations. For example, regardless of if the user logs in during the early hours of the morning or late in the night, the LSTMNet cannot adapt to these contextual changes because the context is not even an input to the model.
Another major drawback is the cold start problem for new classes. At Peloton, we release dozens of new classes every day. Since the LSTMNet must learn a separate embedding for each class, this forces us to re-train this model every day with the newest classes in the training data. The cold start problem for new users is a similar problem; without any workout history, the LSTMNet has no information about the user to compute a recommendation.
To address these issues, instead of relying on the model to implicitly capture a black-box representation for each user and class, we would ideally like the model to create representations for each user and class using explicit features and context, as visualized below.

HOW CONTEXT-AWARE RECOMMENDER MODELS WORK
Context-Aware Recommender models are a suite of Click-Through Rate (CTR) models that can flexibly accept any kinds of inputs such as explicit features and user context, no matter if they are continuous or categorical. Specifically, after experimentation, we decided to use DLRM, a deep learning recommendation model open-sourced by Facebook in 2019. As visualized below, DLRM accepts a user-item pair as an input and outputs the probability that the user interacts with the paired item.

Thus, the input features can largely be split into user information and item information, and within each group, it can be split into static and dynamic features. Please see the table below for specific examples.

In this paradigm, we do not learn embeddings for each individual class in our library. Instead, each class is represented by its metadata, so there is no need to retrain the model like in the case of the LSTMNet, as typically all the attributes of newly released classes have already been seen in existing classes. In addition, even for new users, the cold-start problem is mitigated compared to the LSTMNet, as the model can still infer some information from the static features of the users. Similarly, in “chilly” start settings where an existing Peloton Member onboards to a new platform, context-aware models will already have some idea of kinds of content the user prefers. By making our recommender systems context-aware, we achieve one central system that will be able to handle all cohorts of users regardless of their current stages in their journey of fitness.
SHIFT FROM BATCH PROCESSING TO ONLINE INFERENCE
One important observation to note about using real-time context, such as hour of the day, as an input to calculate recommendations is that the model must also make the predictions in real-time. However, currently our system generates recommendations via daily batch processing jobs, where recommendations for each user are generated and cached to be simply retrieved when a user logs in. Therefore, in order to truly utilize context-aware models, we must transition through to online inference.
This paradigm shift is far from trivial, and our team has decided to undertake this journey in two-stages. We first develop a pipeline that trains and does batch inference with DLRM that has comparable performance as the LSTMNet. Then as the second stage, we would move the inference portion to online, where DLRM would then be augmented with real-time context features. For more details on the tools used to build the system, here is a talk from our team at NVIDIA’s GTC 2020 conference. At this time, we have completed the first stage of this monumental change, and in doing so, we learned multiple major lessons on iterating on recommender systems.
WHERE THE RUBBER MET THE ROAD: LESSONS LEARNED
Make Each End-to-End Iteration Quick as Possible
Building machine learning models is all about trying out as many ideas as possible, as quickly as possible. This is especially true when developing a context-aware model, since there are suddenly infinitely more knobs to tune. We didn’t quite have this problem in the LSTMNet, since the only input is the workout history of users for that model. With context-aware models, we have the gift and the curse to explore infinitely more combinations of different features, feature preprocessing methods, as well as methods of generating positive and negative samples. This project was one of the first major iterations on our machine learning pipeline, and we learned that it is absolutely crucial to make each end-to-end experimentation of an idea as quick as possible.
In the early days of the project, it took hours to go through the whole offline experimentation cycle of preparing the training data, preprocessing the data, training the model, and evaluating the model. Quickly, we realized that we needed to make two changes: enable parallel experimentation and make each experiment quicker by downsampling the data.
By enabling parallel experimentation, we could kick off multiple experiments concurrently with different setups and compare them side by side. On the downsampling front, one could downsample the number of users used for evaluation and the training data itself. One may be wary of downsampling both of these data, as evaluating on a subset of users may not give an accurate picture of the whole population, and training on a smaller dataset may hinder models, especially collaborative filtering models, from truly understanding user behaviors.
However, after conducting some experiments, we found out that the evaluation metrics calculated using all the relevant users actually resulted in virtually the same numbers as when we only utilized 5% of randomly chosen users. In addition, models trained on 10% of the data compared to the full dataset only suffered a small drop in offline evaluation metrics. Context-aware models are technically hybrid models, combining elements of both content and collaborative filtering, so that likely enabled the model to still perform decently well even with data from less users. With these changes, we were able to make the entire offline experimentation shorter by an order of magnitude. We did, however, still run experiments on the full dataset from time to time during development to check scalability of new changes.
Invest in Evaluation
Evaluation is undoubtedly the most important aspect of any experiment. Especially in earlier phases of development, it was very meaningful to actually qualitatively assess the output of the model for some real users – typically our teammates so we know their tastes – to sanity check.
In fact, qualitative evaluation has helped us uncover problems with our outputs that we wouldn’t have been able to observe with pure quantitative metrics. For example, our system generates different recommendations for each user for different platforms (i.e. Peloton Bike and Bike+, Peloton Tread, Peloton App, and more) because user behavior changes drastically across different platforms, even for the same user. However, we saw that model output for one of our teammates on the Bike platform put too much weight on an instructor this person has taken non-cycling classes with on the Peloton App but usually avoids on the bike. By detecting insights like this, we were able to more carefully craft some features to improve the recommendations.
However, qualitative evaluation can be cumbersome and is not suitable for every iteration we were making. So we did mainly rely on offline evaluation metrics, such as Mean Average Precision at K (MAP@K), especially after the initial phases of development.
However, it is a frequent problem in the industry that the offline evaluation metrics don’t always correlate to online performance, as confirmed by companies like Pinterest. To confirm if offline evaluation actually helps, we ran a couple multivariate tests where each variant purposefully had varying levels of MAP@K to compare what kind of offline performance each would achieve. The idea is that if we could observe that models with higher offline metrics result in higher online metrics, we can confidently optimize for higher offline metrics during development. Specifically, by using this result, we were able to establish an offline-online metrics correlation chart, illustrated below, where each variant’s performance is plotted on a graph with the X-axis being the offline metric and Y-axis being the online metric.

With this chart, we first gained some confidence that a higher offline metric does result in a higher online metric, and we also started to see the actual mathematical relationship between the two. Theoretically, if we had a perfectly fit offline-online correlation chart, then the life of best fit could approximate the expected lift in online metrics from the lift in the offline metrics. This means that we don’t always have to run an A/B test to confirm if we would get an uplift in online metrics, which would be beneficial as A/B tests take time. While a perfect offline-online correlation chart never exists in practice, this chart effectively dictates how much confidence we could bestow to our offline metrics.
However, this technique had a couple of quirks. First, we found that our online metrics are not always stable, even if we have not made any changes from our side. Our main online metric such as conversion on our recommended classes on the homescreen can vary depending on what else may be happening that week on our platforms. For example, if there is a new type of workout class being released or some sort of a special event ongoing, it could sway users away from their usual habit of taking their recommended classes. At Peloton, running different multivariate tests to keep accumulating more data points for the offline-online correlation chart proved to be very unreliable due to the forever evolving landscape of our content.
Therefore, an offline-online correlation chart is a tool that can help you locate metrics to loosely trust, but it is still far from perfect. Consequently, our team is looking to develop more sophisticated offline evaluation techniques involving page simulation and replay to add to our arsenal of evaluation approaches.
Invest in Experiment Tracking Tools
We log and store all the metrics as well as model artifacts from every step of the training and evaluation pipelines in MLFLow. This includes metrics like size of training data, the ratio of positive to negative examples, used features, various evaluation metrics, as well as of course the trained model files. However, with so many experiments running in parallel, it could quickly get messy and you could lose track of which run corresponds to the intended changes. As a result, we plan on investing further into our infrastructure around MLFlow and experiment tracking in general to ease some of the manual experiment tracking that one has to do.
Better Infrastructure Reliability for Better DevEx
We rely on AWS to spin up GPU pods with Kubernetes to run our model training and evaluation jobs. However, due to the ongoing global chip shortage, there were some periods when our jobs could not even be spun up. This hindered developer experience, and we temporarily improved the situation by purchasing reserved instances from AWS. Furthermore, by downsampling the data, we were able to reduce the number of GPUs our jobs needed to iterate during development, which also ameliorated the issue. Our team continues to work closely with other teams to make the developer experience better from an infrastructure standpoint.
BRINGING CARS FULL THROTTLE: WHAT’S PLANNED FOR AHEAD
As we shift gears into the next stage of building out our fully context-aware recommender systems by moving inference to online, there are also other exciting things that we plan on doing with CARs.
Generating Contextual Rows of Content
CARS can be used to expand the variety of rows of content we show on our homescreen. By leveraging the time context, we could create new rows such as “Start your Morning With…” or “End your Day With…” that are filled with content the user may particularly like at those specific times of the day. Other types of possible rows of content may include rows like “To Recover from Yesterday’s 60 Minute Workout…” or “If you are in a Bubbly Mood.”
Multi-headed Predictions
Earlier, we explained that the inputs to the context-aware models are very flexible. The same thing can be said about the outputs of these types of models as well. Traditional CTR models only have one “head,” which predicts if the user will click on the item or not. However, we can modify these models to have multiple heads, where each head predicts something different, thereby making our model learn multiple tasks at once.
At Peloton, most of our classes play multiple songs, which the user can explicitly like during the workout. By using this data, we can add a head to predict if a user will like the music in the class or not, which would let us make music-based recommendations. We will also explore the possibilities of adding other heads to predict other actions, such as bookmarking or sharing to others. With multi-headed predictions, we will be able to create different shelves of content to add to our home screen and beyond.

CONCLUSION
We hope that the learnings shared in this blog could help inform any other teams looking to build out context-aware recommender systems. We have an exciting roadmap ahead as we keep tackling the very rewarding and unique challenges we face at the intersection of recommender systems and fitness. If you or anyone you know are interested in working with us, please visit our careers page and join the ride!