Innovation
Improving Our Subscription Charging Process
Written by Becca Barton and Daniel Bowden
Recently, the Membership Software team (RAMBO) released the final phase of a project to overhaul the mission-critical process that runs daily to charge all of our subscriptions. This process took on average 13 hours to run, failed multiple times per week, and wasn’t scaling with our business. We had two goals with this project: increase reliability and increase scalability. By the end, we had reduced errors by 100%, decreased the runtime by 99%, and set ourselves up to scale effectively in the future as our member base grows.
Where We Started
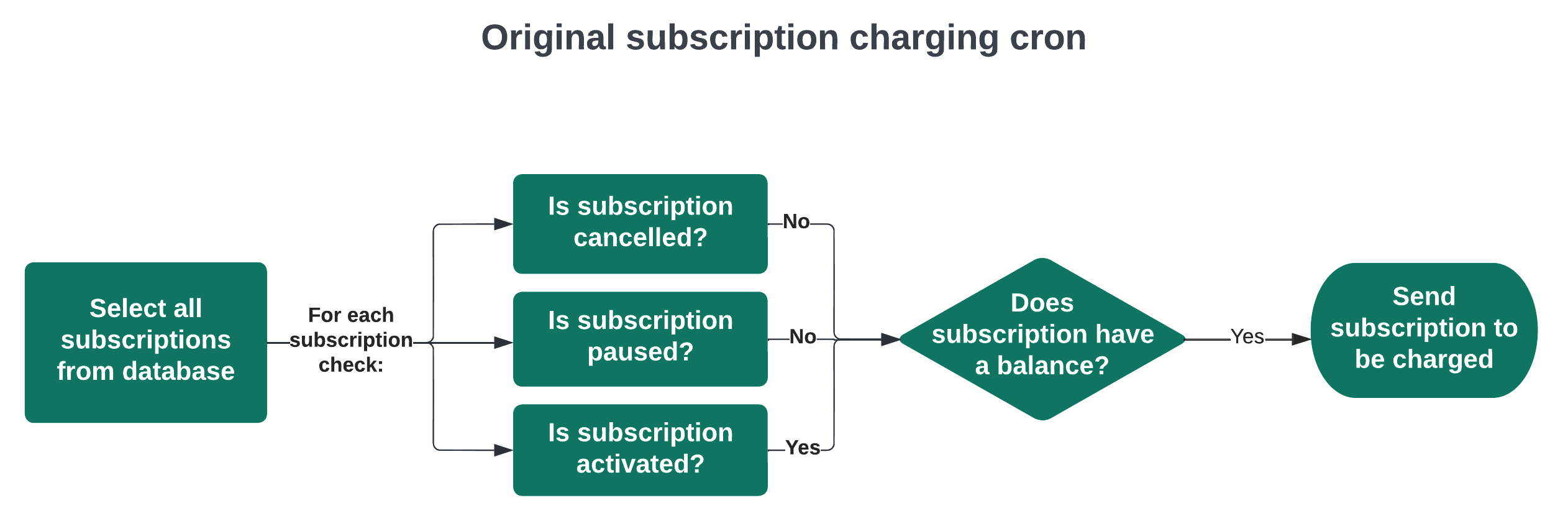
To set context, when we began this project the daily charging process was failing mid run on average 7 times per month (and sometimes as many as 19 times per month). This disrupted our billing schedule, and was also disruptive for our on-call engineers — if you were on-call, you could almost guarantee you’d be paged to restart this process at least once during your rotation. When the process failed, it left the potential for a large subset of subscriptions to be uncharged for the day which would cause a spike in subscriptions entering the grace period mistakenly since they weren’t charged on the day they were due. This caused a lot of errors with our billing reporting. Sometimes we were alerted to these failures and were able to fix them before it had a financial impact, but some failures were silent, meaning we only found out about them after the fact via other reporting mechanisms (for example, increases in soft cancellations happening a few days later).
Aside from the failures, the process also wasn’t scaling effectively with the business. The runtime was very long (averaging 13+ hours) and was increasing by about 30min to an hour month over month. The most pressing issue was that if the cron took a few more hours to run, which it was on pace to do, it would run past midnight. Running past midnight would cause billing reporting errors since subscriptions that were due that day would show up as charged the next day if they were picked up after midnight.
With those problems in mind, we set two main goals with this project:
Increase resiliency and get the cron to a point where it would reliably run from beginning to end without manual intervention.
Increase scalability to ensure that as our business grows, we feel confident that our cron can handle the increased load.
So, how did we achieve those goals?
Understanding The Problem
We started by making sure that before we began, we had a thorough understanding of what the problems were. Sure, we knew the process was flawed, but we wanted to make sure we understood how it was flawed and in what ways it was not meeting our current needs. This meant breaking down all the ways the process was failing now (more on that below) and would fail in the future.
Once we understood what the problems were, we were able to group those problems into two main categories: resiliency, and scalability. Fixing our process’s resiliency would keep it from failing and make it more reliable for the business and less painful for our engineers. Fixing our process’s scalability would give us peace of mind for the future, ensuring we would be able to leave the process untouched as the business grew, vs needing to update it every few months to accommodate subscriber growth.
With the problems categorized, how would we know if we had successfully fixed them? This led us to create success metrics to track the project against. These success metrics were the things we wanted to be able to look back at the end of the project and say, this is what we accomplished. Below is a breakdown of what we pulled out as our success metrics.
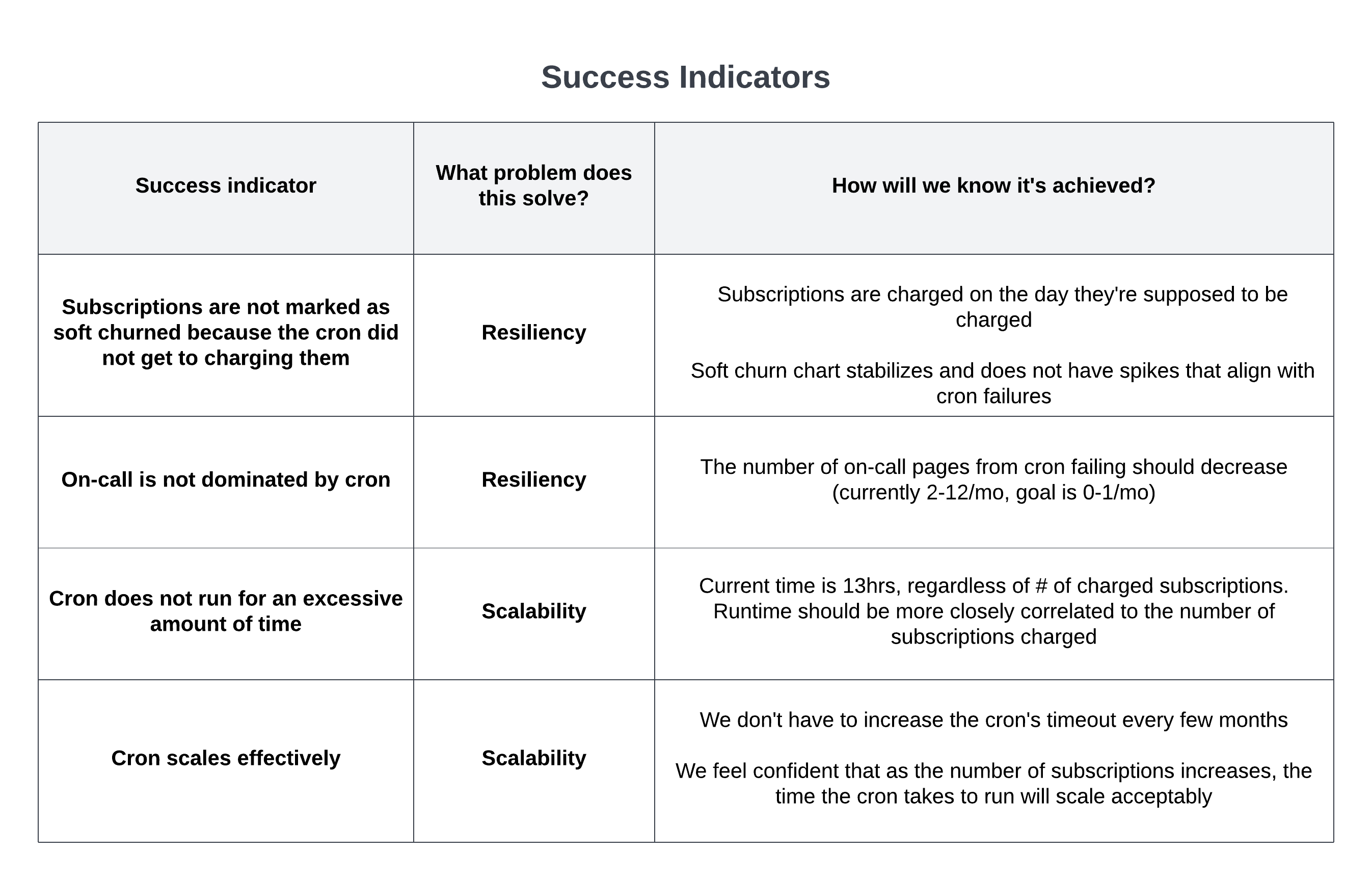
Once we had our success indicators for the project as a whole, we also created success indicators for each of the two project phases. Splitting the project up into separate phases each with their own set of goals allowed us to make meaningful incremental progress, and kept us focused throughout the project by ensuring we were always focused on achieving the goals we set out at the beginning of the project. And by keeping the goals broad instead of specific, it allowed us flexibility throughout the project to change course and accomplish a goal a different way than we originally planned if we found a better way or learned new information.
Increasing Resiliency
To increase resiliency, we needed to understand why it was failing. We did an in-depth analysis of the reasons the process was failing in order to understand where we could introduce fixes.
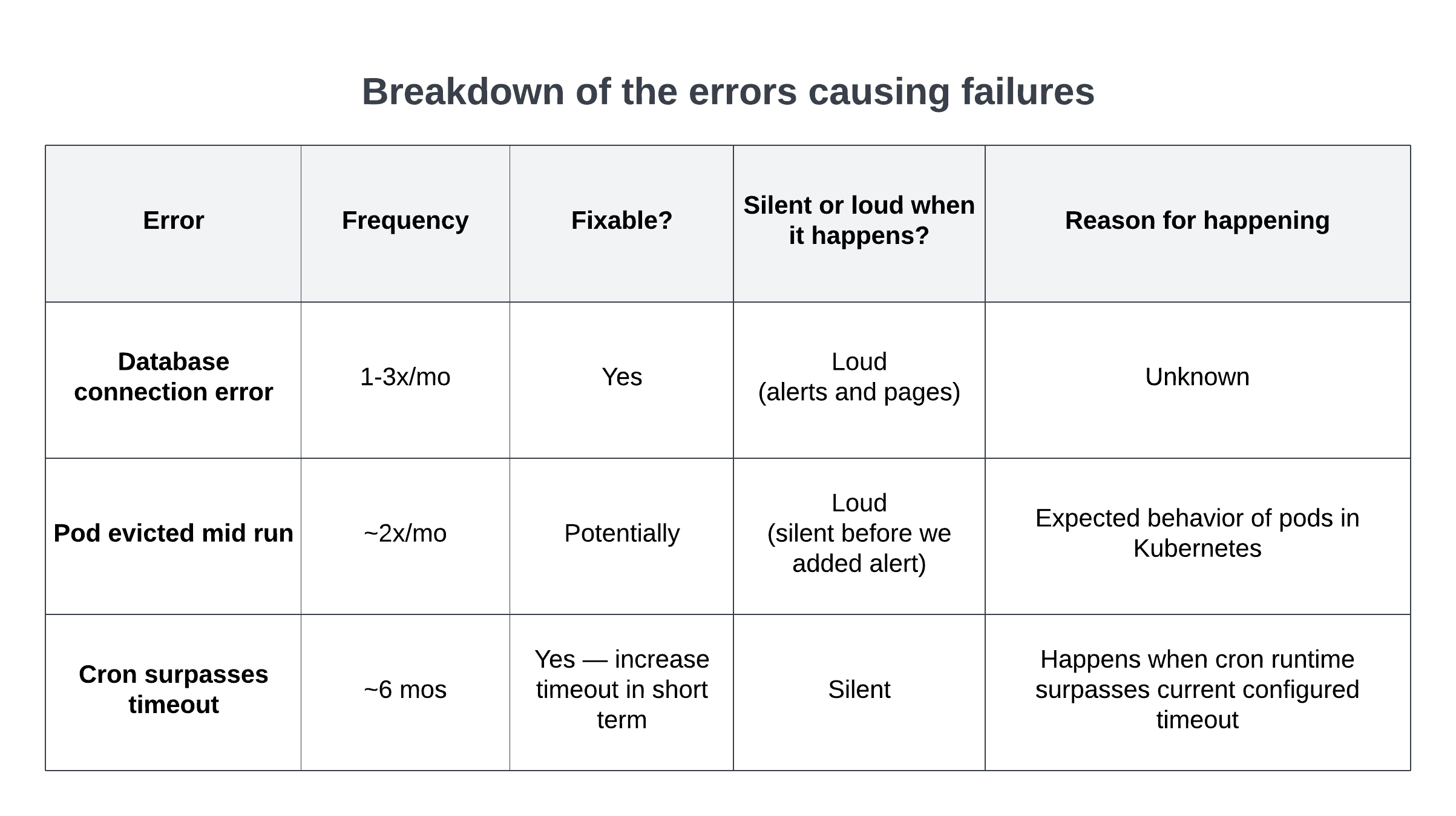
Based on the above analysis, we were able to identify three issues that caused the cron to fail regularly. We ranked them by the frequency of which they occurred, whether they were fixable, and whether we were alerted when they happened. Based on these criteria, we were able to prioritize fixing the underlying cause for one that was fixable, and create monitors and alerts where they were missing. For example, by studying the distribution of errors, we were able to find out the database connection error was accounting for almost all failures, so fixing the underlying issue for that error would have the highest impact on increasing resiliency.
In addition to fixing underlying issues, we also identified where we ran into those issues and added backoff retries so that the process could retry and potentially continue mid run, vs failing completely and requiring manual intervention to restart. The bug fixes helped reduce the number of errors our process experienced during its run, and adding the backoff retry allowed the process to be more resilient in the future.
Once we’d identified fixes for individual parts of the process, we also wanted to allow our process to restart on its own as a whole. Our process runs on Kubernetes, which allows us to automatically restart. We found there was a bug that was causing the exit codes to not be sent when the cron failed, so by fixing that bug and sending the right exit codes during a failure, our cron could now automatically restart on its own if it encountered a fatal error mid-run.

The results of this phase were huge — previously the on-call engineer expected to be paged about the cron at least once during a rotation to restart it. After this phase, we no longer had regular failures (and, fingers crossed, we haven’t had an unexpected failure mid-run since November 2021). This also meant subscriptions were getting reliably charged since the cron wasn’t failing midway through anymore.
Increasing scalability
Decreasing load
For increasing scalability, we wanted to start by reducing the overall load that our cron was operating on. Reducing the load would make it easier in the future to split up and keep it from scaling inefficiently in the future. In our current state, the cron looked at every single subscription record on a daily basis, and determined whether it needed to be charged. Since only a subset of subscriptions are due to be charged on any given day, this was relatively wasteful, inefficient, and was causing our cron to increase in runtime by 30min-1hr every month as our number of subscriptions grew. To reduce the load, we started small and incrementally eliminated records.
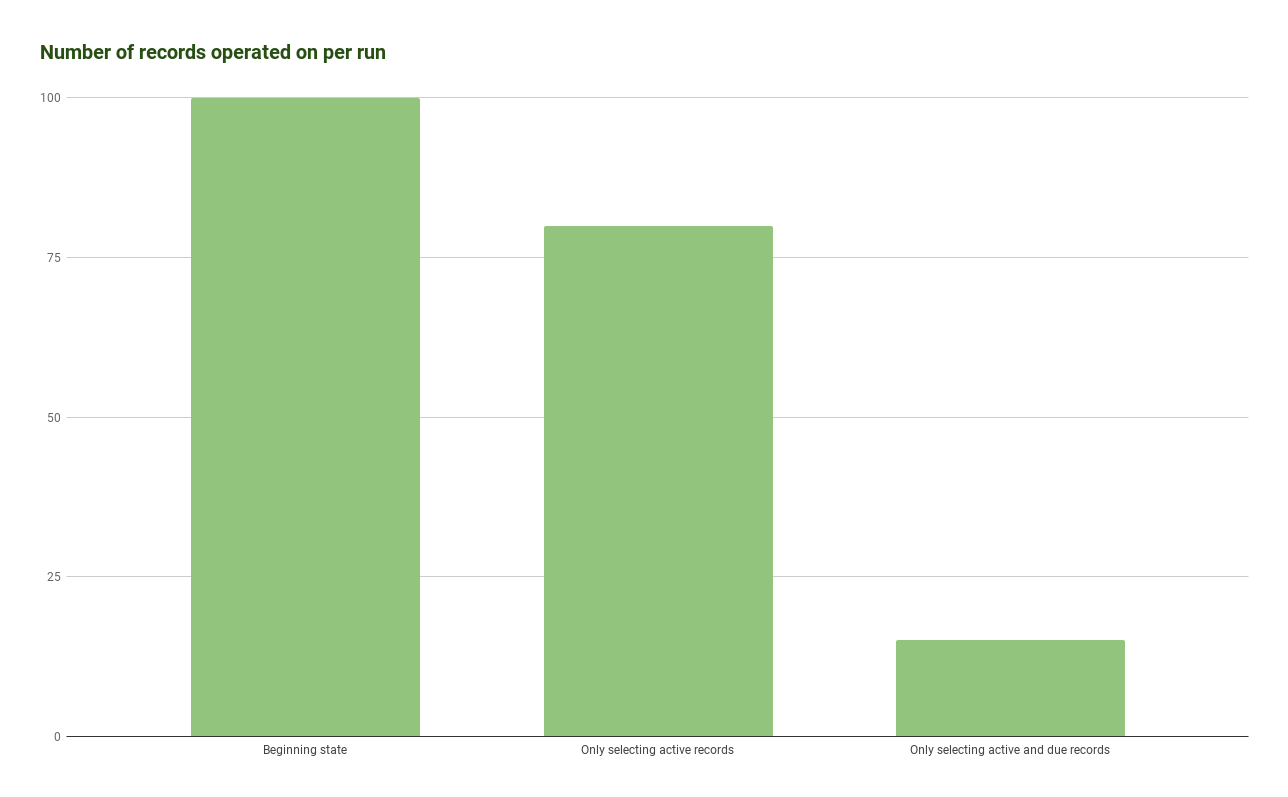
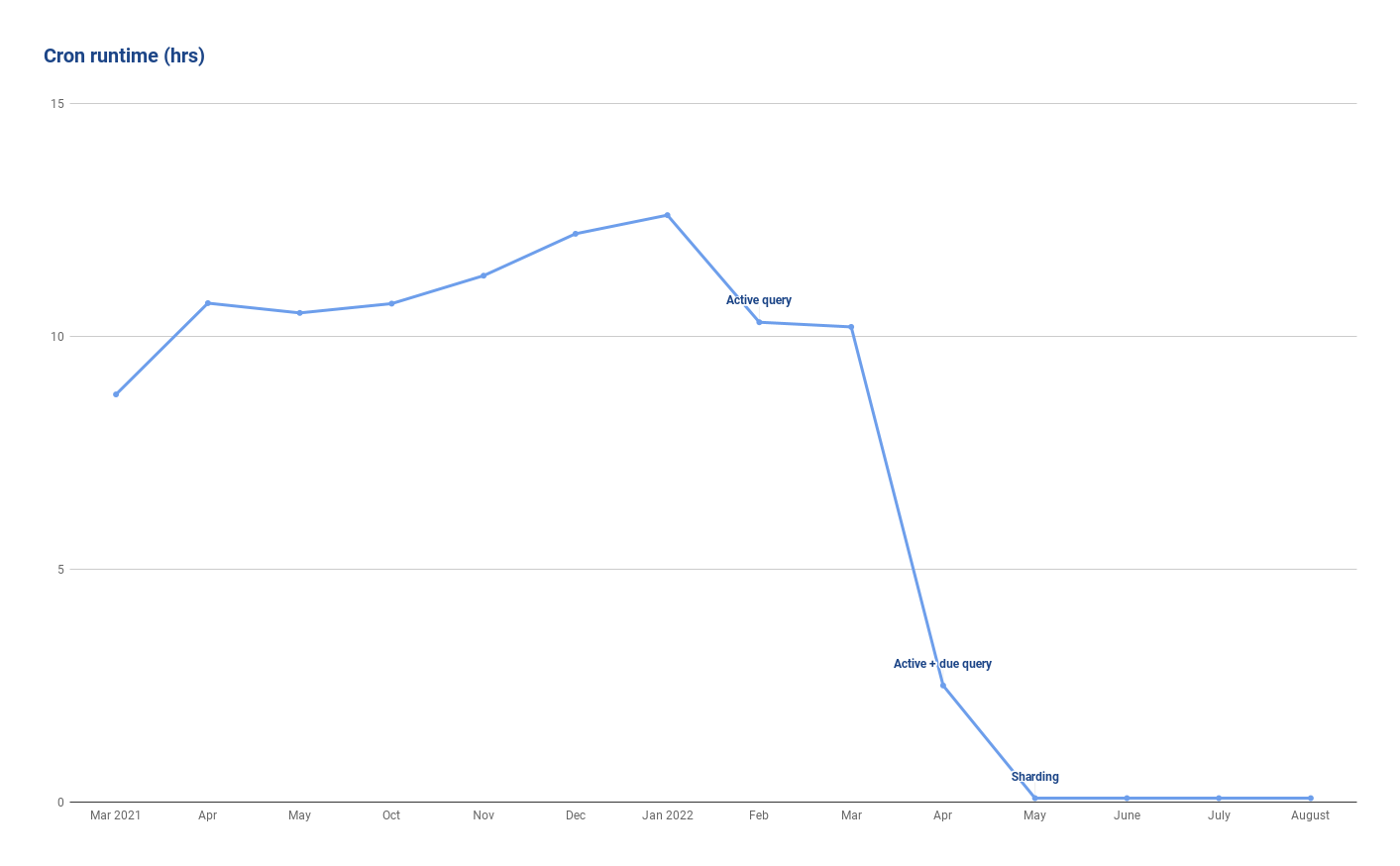
We started by only selecting active subscriptions from the database. This eliminated about 20% of the records since we no longer needed to check if cancelled or inactive subscriptions were due. This also cut our runtime by 20%, and we went from an average of 13 hours runtime to about 10 hours.
Next, we moved the logic of determining whether a subscription had a balance from the code to the database query directly, meaning we only selected subscriptions that had a balance due. This eliminated a further 80% of records to look at. After this phase, on a daily basis we are checking about 15% of the total records — whereas previously we were checking 100% of records. This improved process drastically reduced our runtime, and got us down to a runtime of about 2 hours. This all set us up for success as we investigated the next step.
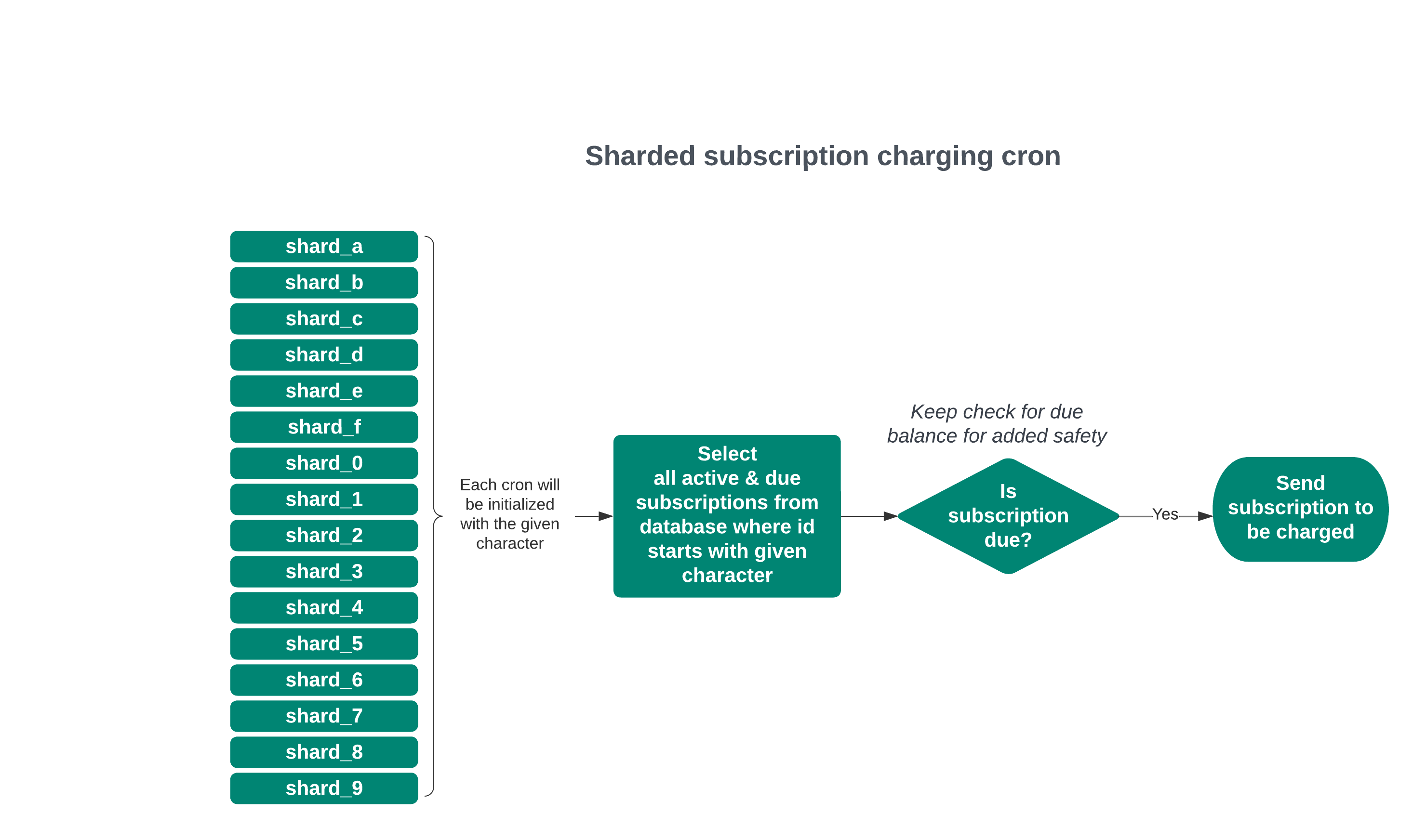
Introducing sharding
Once we reduced the overall load of the cron, we need to make sure our cron could scale effectively with the business in the future. Our ultimate goal here was to turn this from a process we thought about constantly, to one we didn’t have to think about at all. In order to do that, we introduced sharding to the cron, which allowed for multiple processes to split up the total load of the one cron and instead operate on a subset of the records concurrently.
To keep it simple, we decided to split into 16 processes split by the first character of the subscription’s UUID. Since UUIDs are randomly generated, we expected that this would be a way to evenly distribute the load across all shards. This meant that whereas the previous version operated on all the records, now at the same time, we’d have 16 versions of the cron each operating on 1/16th of the records at the same time. This dropped our runtime dramatically — it went from about 2 hours down to just 5 minutes.
How did we do this safely?
Remarkably, we were able to release all these changes with minimal negative impact in production. This was because we set up a thorough testing framework that allowed us to feel confident in every release because we’d worked out the bugs beforehand.
While we were able to run any changes we made locally and add tests, we realized early on that we needed a way to operate on production data and compare our changes to the current version running in production. To accomplish this, we set up two “shadow” crons, baseline and sandbox. Sandbox would be where we tested our new changes, and baseline would match the version that was running in production. Neither actually charged subscriptions, but they would log out the records they determined needed to be charged so we could compare.
Because we logged out the discrepancies between the old version and new version without actually changing data, we were able to catch any missing pieces and fix them before a release. For most changes, we let the versions run in production for a full billing cycle, or one month, in order to make sure we had a full picture of how the changes would affect the process. This also meant that by the time we were ready to roll out the next change, we were fully confident in our release.
Where We Ended Up
So, how did we track against our goals? For resiliency, we reduced runtime failures by the cron, from 7 runtime failures a month down to 0 runtime failures a month. This also decreased our number of on-call pages due to cron failure down to 0, which was a huge relief to our team, and for the business. As part of this effort, we added additional alerting and monitoring, and everything is tracked against SLOs so we have full visibility into the health of this process.
For scalability, we reduced the runtime of the cron from an average of 13.5 hours down to 5.5 minutes. This not only gets us to a better place now, but sets us up for growth in the future. By sharding our process, we’ve set up a framework that we can easily extend as we grow in the future. We were also able to load test it and verify it would be able to handle a >150x increase in subscriptions, which gives us great confidence we won’t have to think about this process again for a long time.